Instabase architecture
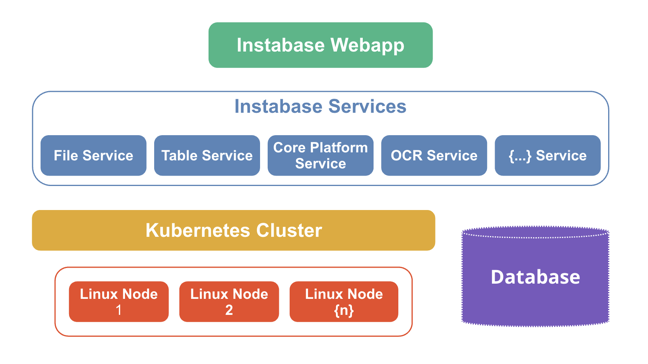
The Instabase webapp runs as a collection of services, which are packaged as Docker containers and deployed in a Kubernetes cluster.
In the cluster, each Instabase deployment represents an Instabase service. The number of pods for each deployment can grow and shrink depending on the load.
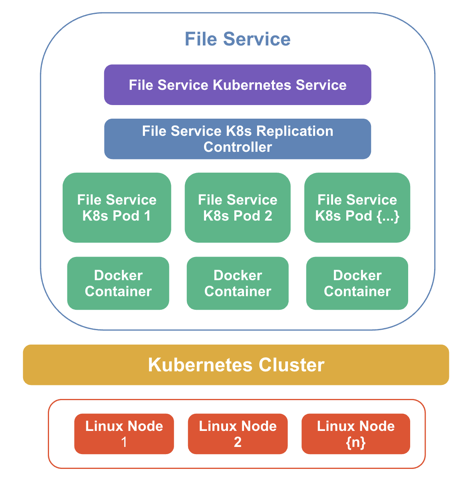
An individual service runs replicated pods to enable fault tolerance, ensuring that services are up and running even when some of the underlying machines fail or restart. For example, in the following diagram, the file service and file service controller are running on multiple pods and containers in the cluster.
Architecture design principles
Instabase features scalability, availability, security, and portability at both the infrastructure and application levels.
Instabase tools and applications are architected on microservices that are packaged as Docker containers and deployed as pods inside a Kubernetes cluster. The platform optimizes the cost of infrastructure by efficiently distributing the workload across multiple machines in a cluster.
Kubernetes offers freedom of choice when choosing operating systems, container runtimes, and cloud platforms. A Kubernetes cluster can be configured on mainstream Linux distributions, including CentOS, Debian, and Ubuntu, and deployed to run on:
-
Local development machines.
-
Cloud platforms such as AWS, Azure, and Google Cloud.
-
Virtualization environments based on KVM, vSphere, and libvirt.
-
Bare metal.
Availability and fault tolerance
Instabase uses Kubernetes Replication Controllers for availability and fault tolerance. Depending on the workload, you can declare the minimum number of pods that need to run at any given point of time. If a container or pod crashes, the declarative policy can bring back the deployment to the desired configuration.
We recommend a configuration with a minimum of 12 replicas, which ensures that if a pod crashes due to some failure, Kubernetes automatically brings up new pods to ensure that at least 12 replicas are always running.
Scalability
Linear scaling is achieved by adding CPUs and RAM to the cluster. In general, Instabase relies on horizontal pod autoscaling (HPA) with the Kubernetes autoscaler, automatically scaling the number of pods in a replication controller.
Scaling happens based on the collective CPU utilization of the pods at the service level. If the CPU utilization for the service goes above 50 percent, the autoscaler adds pods in the cluster to ensure the system can grow to handle a sudden spike in the workload. Most deployments have minReplicas and maxReplicas values that are set based on the amount of available resources (as described by the client), and their peak throughput estimate. Successful autoscaling requires provisioning the cluster with enough resources to enable scaling up to the configured maxReplicas number of pods.
AWS, Google Cloud, and Azure also support cluster auto-scaling. When pods are scaled across all available nodes, Kubernetes coordinates with the underlying cloud provider to add additional nodes to the cluster.
Fault tolerance and resiliency
All Instabase services are designed to be fault-tolerant and scalable using a configured set of replica counts. The Kubernetes cluster architecture ensures that the replica count is maintained. If a pod crashes, the Kubernetes master node brings up another instance of the pod to maintain the replica count.
Network protocols
Instabase uses both stateless and stateful network protocols.
Most services are stateless. For stateless services, at least two replicas are required. If one of the replicas is down, the service can still serve traffic on the running replica. To provide scale, it can be reasonable to have tens to hundreds of replicas.
The few stateful services are rabbitmq and redis. These services run in a singleton mode. To ensure durability, these services are backed with a persistent volume. Even if the Kubernetes pod goes down, data loss does not occur and when the pod is back up, regular work can be resumed. Instabase services are configured to use rabbitmq and redis to retry during a restart so that running flows can auto-restart if the redis and rabbitmq services stop while a flow is running.
Pod failures and retries
Pod failure is inevitable in a running system. Retries occur in the Instabase platform to ensure continuity of service during pod restarts:
-
For all RPC services, a built-in retry mechanism of retry count and retry delay is applied. This retry mechanism is internal to Instabase and is not configurable by design.
-
For celery-workers, the automatic retry mechanism of celery automatically manages pod failures.
File system
The Instabase file system provides a uniform interface for managing files and folders. Like a typical filesystem, it supports standard file/folder operations such as copy, rename, delete, move, upload, and download.
You can mount existing file storage systems, such as Amazon S3, local network file system (NFS), Azure Blob storage, or Google Cloud Storage to the Instabase filesystem. Instabase apps run on your data without moving the data out of your existing storage systems.
This model also allows for security enforcement: all the security management on Amazon S3, local NFS, Azure Blob storage, or Google Cloud Storage automatically applies to Instabase.
Database
Instabase databases provides a uniform interface for managing SQL databases. You can create a new database (hosted & managed by Instabase) or mount an external database such as MySQL, PostgreSQL, Oracle, and Microsoft SQL Server.