Provenance Tracking - Extracted Tables
About Extracted Tables
Extracted tables are tables extracted by table extraction models. In order to provide provenance information for each table’s cells, there are special data types to represent extracted tables. See provenance tracking to learn more about how provenance is tracked in general.
In particular, a table extraction model’s fields in Refiner are ExtractedTablesList objects, which represents a list of tables. UDFs can return an ExtractedTablesList object or an ExtractedTable object, which represents a single extracted table.
Refiner has 2 output types "Extracted Tables List", "Extracted Table" to display the ExtractedTablesList, ExtractedTable data types, respectively.
instabase.provenance.table.ExtractedTablesList class
This type represents a list of ExtractedTable objects.
Accesing the list
# Returning an ExtractedTablesList object with 1 table
def example_udf(tables: ExtractedTablesList, ...) -> ExtractedTablesList:
# Get a copy of the first table in the list
t1 = ExtractedTablesList[0].get_copy()
t1_modified = # some operation on t1
return ExtractedTablesList(t1_modified)
# Returning an ExtractedTablesList object with multiple tables
def example_udf(tables: ExtractedTablesList, ...) -> ExtractedTablesList:
# Get a copy of the first table in the list
t1 = ExtractedTablesList[0].get_copy()
# Get a copy of the second table in the list
t2 = ExtractedTablesList[1].get_copy()
t1_modified = # some operation on t1
t2_modified = # some operation on t2
return ExtractedTablesList([t1, t2])
Iterating through the list
# Returning an ExtractedTablesList object with multiple tables
def example_udf(tables: ExtractedTablesList, ...) -> ExtractedTablesList:
filtered_tables: List[ExtractedTable] = []
for table in tables: # each `table` object is an ExtractedTable object
if table satisfies certain conditions:
filtered_tables.append(table)
return ExtractedTablesList(filtered_tables)
instabase.provenance.table.ExtractedTable class
This type represents a single extracted table and holds information about the bounding boxes of its cells, as well as provenance information for the text in each of the cells.
Getting the dimensions of a table
The shape function returns a tuple where the first element is the number of rows in the table, and the second element is the number of columns in the table.
def shape(self) -> Tuple[int, int]:
"""Returns the table height and width as a pair of integers.
"""
Getting a table cell’s value
An ExtractedTable object can be accessed by its row and column indices. This operations returns a Value[Text] object containing the content of the cell at that row and column index.
def example_udf(t1: ExtractedTable, ...) -> Value[Text]:
# Get the content in the cell at the 2nd row and 3rd column.
return t1[1, 2]
Slicing the table
An ExtractedTable object can be sliced by its rows and columns. This operation returns a copy of the original ExtractedTable object with the new cells.
def example_udf(t1: ExtractedTable, ...) -> ExtractedTable
# Gets all rows but only the 2nd and 3rd columns
table_sliced = t1[:, 1:3]
# Gets the 4th row and all but the first 2 columns.
table_sliced = t1[3, 2:]
# Gets a table with the 2nd-4rd rows and 4th-5th columns.
table_sliced = t1[1:4, 3:5]
Iterating through the cells of a table
You can iterate through an ExtractedTable object to go through each cell in the table and modify those cells in-place. See the ExtractedTableCell type for more information about the cell type.
def example_udf(tables: ExtractedTablesList, ...) -> ExtractedTablesList:
# Get a copy of the first table in the list
t1 = ExtractedTablesList[0].get_copy()
for cell in t1:
# Add a dollar sign to all cells in the 2nd column
if cell.col_start_index == 1 and cell.row_start_index > 0:
cell.text = '$' + cell.text
return t1
Combining tables together
@staticmethod
def concat(tables: List[ExtractedTable], as_row: bool = True) -> ExtractedTable:
Tables can be combined together, both column-wise (the resulting table is wider) and row-wise (the resulting table is taller), using the concat function. This static function takes in a list of tables.
# Combining row-wise:
## Combining all of the tables in an ExtractedTablesList object
ExtractedTable.concat(ExtractedTablesList.value(), as_row=True)
## Combining a list of ExtractedTable objects
ExtractedTable.concat([t1, t2, t3], as_row=True)
# ----------------------------------------------------------------
# Combining column-wise:
## Combining all of the tables in an ExtractedTablesList object
ExtractedTable.concat(ExtractedTablesList.value(), as_row=False)
## Combining a list of ExtractedTable objects
ExtractedTable.concat([t1, t2, t3], as_row=False)
Adding rows and columns to a table
The above concat function can be used to add columns or rows to a table. For example, lets say you have a Refiner field that contains a list of extracted tables, one of which is the following bank statement:
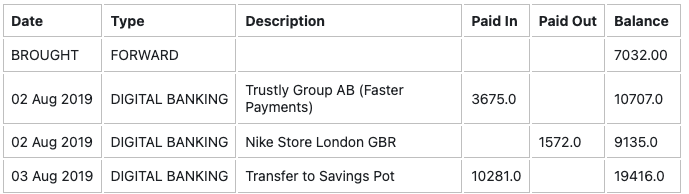
The function normalize_table below will find the above table and return a new table that has an additional column named "+/-" that shows the net change to the balance.
def col_idx_with_header(table: ExtractedTable, col_header: Text) -> int:
"""Returns the column index in the table with the given column header"""
for i in range(table.shape()[1]):
if table[0, i].value() == col_header:
return i
def amt_to_float(str_val: Value[Text]) -> float:
"""Converts the string value to a float"""
val = str_val.value().strip()
if not val:
return 0
return float(val.replace(',', ''))
def normalize_table(tables: ExtractedTablesList, **kwargs: Any) -> ExtractedTable:
"""
Adds a column in the table in the given list of tables whose top left
cell has the text 'Date'. This column shows the net change to the balance
"""
for t in tables:
# Get the table whose top left cell has the text "Date"
if t[0, 0].value() == 'Date':
# Get the column index of the "Paid In" column
paid_in_col = col_idx_with_header(t, 'Paid In')
if paid_in_col is None:
return
# Get the column index of the "Paid Out" column
paid_out_col = col_idx_with_header(t, 'Paid Out')
if paid_out_col is None:
return
# Get a copy of the "Paid In". We will modify the cells in this column
# to produce the new "+/-" column.
net_col = t[:, paid_in_col]
for row_idx, cell in enumerate(net_col):
if row_idx == 0:
# Set the header of the column
cell.text = Value('+/-')
elif row_idx > 1:
# Skip the "Brought Forward" row
# Calculate the net change
paid_in = amt_to_float(t[row_idx, paid_in_col])
paid_out = amt_to_float(t[row_idx, paid_out_col])
net = paid_in - paid_out
# Set the value of this cell based on the net value. The `text`
# field of a cell has to be a Value[Text] object
if net < 0:
cell.text = Value(str(net))
elif net > 0:
cell.text = Value('+' + str(net))
else:
cell.text = Value('0')
# Add this column on the right of the existing table
return ExtractedTable.concat([t, net_col], as_row=False)
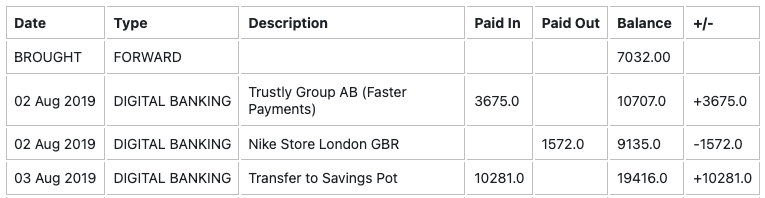
The result of calling the normalize_table function is the following table:
Getting a copy of a table
To get a copy of a table, you can either slice the table or call the get_copy method. See below:
# Ways to get a copy of a table
## 1.
table_copy = table.get_copy()
## 2.
table_copy = table[:,:]
instabase.provenance.table.ExtractedTableCell class
This class represents a cell in an ExtractedTable. This is the type that is returned when iterating through an ExtractedTable object (see iterating through an extracted table), and it has the following fields:
# The provenance-tracked text in this cell.
text: Value[Text]
# the row that this cell starts on
row_start_index: int
# the row that this cell ends on (same as row_start_index if this cell is not a merged cell)
row_end_index: int
# the column that this cell starts on
col_start_index: int
# the column that this cell ends on (same as col_start_index if this cell is not a merged cell)
col_end_index: int
Note that the text field has to be a Value[Text] object, not a Value[int] object or anything else.
Getting a copy of a cell
To get a copy of a cell, you can call the get_copy method.
for cell in table:
cell_copy = cell.get_copy()
...