
Overcoming the Limitations of LLMs: Advanced Content Digitization

Businesses generate and handle vast amounts of documents daily. Document understanding is foundational to solving multiple business challenges, from automating document-heavy processes and searching enterprise data to managing organizational content.
With the popularity of LLMs such as ChatGPT, it may be tempting for organizations to simply copy and paste documents into ChatGPT, assuming that the outputs will be sufficient for document understanding. But that is not the case. To get the most from your data, you need more than LLMs. In this series, Overcoming the Limitations of LLMs, we'll address the biggest challenges in applying LLMs to document understanding, starting with why layout, quality, and visual elements are essential to accurate interpretation.
By leveraging advanced content digitization techniques, we can address these limitations and provide LLMs with the semantic information to understand complex documents.
Understanding Document Structures for Content Digitization
To achieve true document understanding, it is essential to do more than simply digitize a document through a scanning function. Here’s why.
Complexity of Document Structures
Business documents such as invoices, contracts, and medical claims are inherently structured to convey semantic meaning that humans can understand. This structure, often in the form of tables, sections, and visual elements, is crucial for accurate understanding and processing. For instance, the layout of an invoice includes specific placements for items, prices, and totals, which are essential for correct interpretation.
One-Dimensional vs. Two-Dimensional Understanding
LLMs traditionally process text in a linear, one-dimensional way, which is suitable for tasks like sentiment analysis of social media posts. However, this approach is insufficient for documents with complex layouts. This example shows how document layout is crucial to understanding context such as the difference between the vendor and customer address or how table rows and columns line up with their respective headings. The table's spatial arrangement provides context that is lost when converting the information to plain one-dimensional text for LLMs.
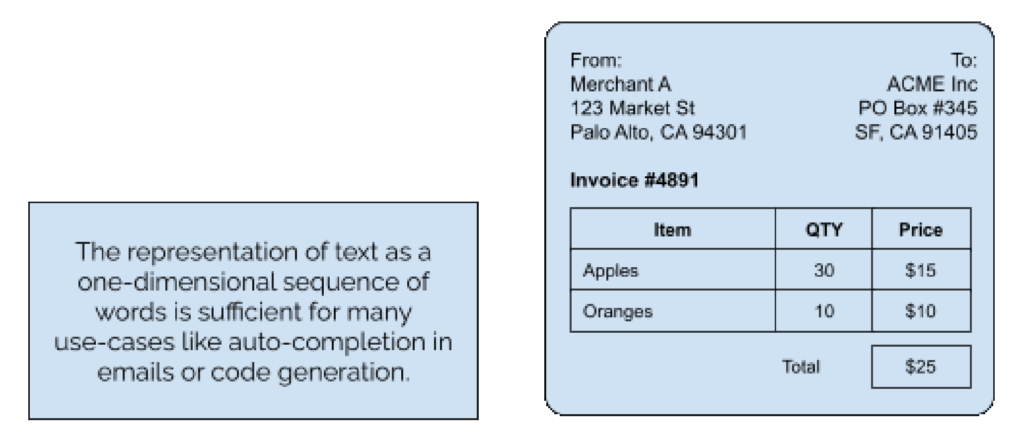
Once that information is lost, no LLM can answer questions about the document accurately. So, to solve this problem, you must first correctly parse any type of document and create a rich content representation. Let’s explore digitization and parsing techniques further.
Digitization and Parsing Techniques
Documents come in various formats, including PDF, DOCX, EML, and JPEG, each posing unique challenges in digitization. Some formats contain embedded text and layout information, while others, like scanned images or pictures of documents, require sophisticated pre-processing techniques.
Pre-Processing Techniques
Pre-processing steps such as auto-rotation, deskew, and unblur are essential for optimizing the quality of digitized documents. For example, deskewing a scanned invoice ensures that the table rows align correctly, facilitating accurate data extraction. By using an array of automated corrections, Instabase AI Hub is able to maximize the quality of the outcome.
Once those corrections have been applied, the next step is to correctly parse diverse types of content, such as handwriting, tables, digital text, etc.
Text and Handwriting Recognition
Instabase AI Hub employs a variety of OCR engines tailored to different document types, including those with handwritten text. For handwriting, Instabase starts by detecting the language and character set, then chooses the appropriate OCR for the task. This ensures high accuracy in text recognition across diverse documents, from printed invoices to handwritten notes.
Tables and Complex Data Extraction
Extracting data from tables is particularly challenging due to the loss of visual cues (borders and shading) and the potential for exceeding LLM context windows. Instabase AI Hub addresses these issues with computer vision-based models and custom algorithms that accurately detect and represent tables, even spanning multiple pages.
Content Representation
Creating “Digital Clones”
A key innovation of Instabase AI Hub is the creation of a proprietary format that acts as "digital clones" of documents. These digital replicas retain the original content, structure, and style, enabling LLMs to understand and reason about the content in a two-dimensional manner. This preserves critical characteristics like layout and formatting, which are essential for accurate document understanding.
Here’s an illustration of how a “digital clone” of a document contains all of the relevant information, style, layout, etc. in a cleaned-up, machine-readable format.

Instabase AI Hub Tackles Complex Document Understanding
For businesses looking to enhance their document understanding capabilities, exploring Instabase AI Hub is a compelling option. Its advanced content digitization techniques and robust parsing capabilities provide a comprehensive solution to the limitations of LLMs, ensuring that critical document structures and semantics are preserved.
Digitizing and parsing documents correctly is the first step in achieving accurate, automated document understanding. Representing the content you have digitized is the next step.
[[component]]
Further Reading

%20(2).png)
.png)
.png)
